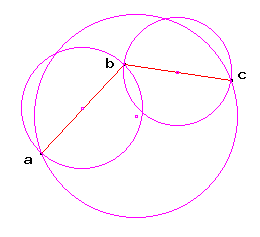
One such proximity graph is the Gabriel graph:
given a set of points in the plane, two points are connected by an
edge ab if there are no other points inside the
circle having ab as a diameter. For example:
The Gabriel graph (as well as the Relative Neighborhood graph) are in fact particular cases of a continuous family of proximity graphs called Beta-skeletons. In these graphs, the "forbidden region" around two points is defined according to a positive parameter Beta.
An intuitive explanation of Beta-skeletons is through an analogy with patterns of roads [6]: a road connecting two cities will most likely follow the shortest path (straight line) unless there is a third city only a "small detour" somewhere along the way.
The basic idea is to try to identify the "rogue" samples by examining their neighborhood. Under the assumption that most of the samples in the set are correctly labeled, an incorrectly labeled sample will likely have most of its neighbors from a different class.
What is the neighborhood of a sample? It is defined by the proximity graph of the entire set: two samples are (graph) neighbors if they are directly connected by an edge in the graph.
Here is the editing method :
|
Note that the order in which the set is processed does not matter: the method deletes samples in parallel (all at the same time, in step 3).
Here is an example:
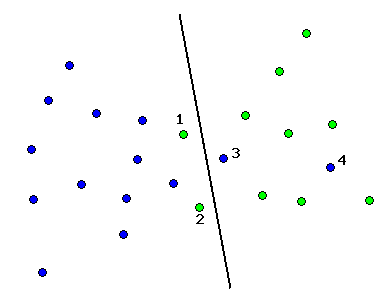
Now, let's apply the above method: first, build a proximity graph
(Gabriel graph in this example) for the set.
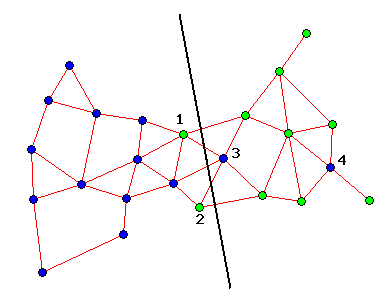
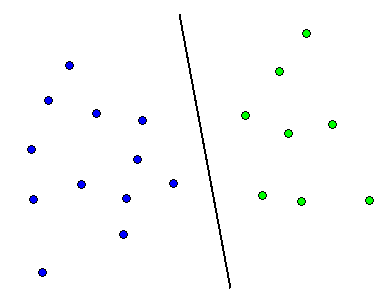
Note: in general, the above editing method may not clean all
the "rogue" samples from the training set. However, the
method can be applied again on the new training set.
| Table of Content | WHAT and WHY | HOW | SHOW ME | FURTHER INFO |
|---|