In practice however, collecting a sufficient number of training samples and correctly labeling them can be a tedious, if not impossible, task. Thus, practical supervised classifiers are better described as "imperfectly supervised classifiers".
Moreover, some classification problems exhibit a certain inherent overlap between the class distributions in feature space. This overlap can confuse a supervised classifier during training ("What do you mean this apple is neither small, neither big, but somewhere in between?").
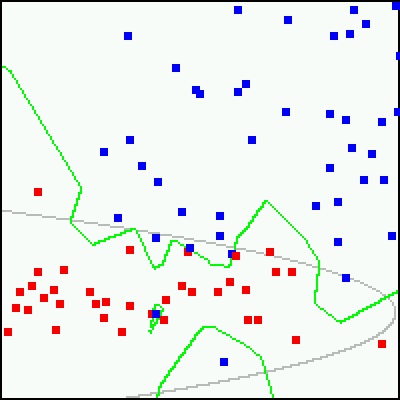
The Nearest-Neighbor classifier has several advantages: it is very simple (easy to implement and easy to understand), and does not make any assumptions about the data distributions in feature space (it is non-parametric). However, it trusts the training samples to be correctly labeled! For example, here is a training set, the decision boundary determined by the NN classifier (shown in green), and the boundary determined by a Bayes classifier, assuming Gaussian data distributions (shown in gray):
Note that the NN classifier fitted the training data very closely. However, because of the "rogue" samples, and because of the small number of training samples, the resulting boundary looks un-natural. In contrast, the Bayes classifier determined a boundary based on statistical measures from the data (mean, variance), and this boundary is more likely to be true (hence, correctly classify new samples) on these particular data.
In conclusion, an automatic method of editing the training set to remove the "bad apples" from it (that is, both obviously mis-labeled samples and samples lying at the overlap of the class distributions in feature space) is of high practical interest.
Another frequently used meaning of editing is for an
operation that reduces the size of the training set, in such a way
that the decision boundary (of a NN classifier) is not distorted
significantly. This is also known as condensing or
reducing the training set.
| Table of Content | WHAT and WHY | HOW | SHOW ME | FURTHER INFO |
|---|