Let x1 denote either a variate or a computed discriminant function with distance ![]() ,
and let x2 be the new variate to be added to the first one, or to some already constructed LDF, at which we can look as at an variate itself. Signs of correlations are of crucial importance, and we will assume that the positive correlation coefficients mean that the intra-class correlation has the same sign as the correlation between the means of two classes.
,
and let x2 be the new variate to be added to the first one, or to some already constructed LDF, at which we can look as at an variate itself. Signs of correlations are of crucial importance, and we will assume that the positive correlation coefficients mean that the intra-class correlation has the same sign as the correlation between the means of two classes.
Usually, in cases of natural applications positive correlations are more frequent than negative, because we commonly have different kinds of tests which make categorization either into two simple classes (yes-no, pass-fail, etc.), where most often the ''yes'' class has higher score, and hence, shows positive distance given by its mean value in the second class, ![]() .
That gives rise to positive correlation between classes. Also, one good performance accompanies another, thus, the intra-class correlations are positive as well. In spite of being rare, negative correlations can occur (Iris example of Fisher, 1936). But, how to actually calculate the increase in squared distance due to inclusion of the new variate x2? Let's try with the following 'trick': variate
.
That gives rise to positive correlation between classes. Also, one good performance accompanies another, thus, the intra-class correlations are positive as well. In spite of being rare, negative correlations can occur (Iris example of Fisher, 1936). But, how to actually calculate the increase in squared distance due to inclusion of the new variate x2? Let's try with the following 'trick': variate
![]() is independent of x1 and has the distance between classes
is independent of x1 and has the distance between classes
![]() -
-![]()
![]() ,
and variance
,
and variance ![]() .
Knowing this, it is easy to see that the squared distance increases by the amount:
.
Knowing this, it is easy to see that the squared distance increases by the amount:
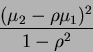 |
(30) |
At the beginning of this section we have assumed that variates that are to be examined (whether to include them into LDF or not) show ''poor''performance as discriminators. For a given ''new'' discriminant x2 the distance it preserves between classes is just a fraction of the established discriminator's distance- in other words:
![]() ,
where f is in the [0,1] interval.
,
where f is in the [0,1] interval.
We can play further and express the increase of original distance as a fraction of itself:
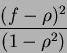 |
(31) |
For ![]() the increase in distance is reduced to f2. Thus, correlation is helpful if it is satisfied:
the increase in distance is reduced to f2. Thus, correlation is helpful if it is satisfied:
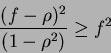 |
(32) |
Conclusions:
For the positive correlations, we can further conclude that if we are to take a new feature with equal discriminating power (f=1), then all positive correlations are harmful; and for f=0, which means that the new feature has no discriminating power then all positive correlations are helpful (as well as negative).
If we want, by introducing a new discriminant, to obtain a significant increase of the goodness of overall LDF, meaning- the increase of its discriminating power- then the new feature (discriminator, or covariate) has to bring with itself a high level of correlation with the old feature or overall discriminator. Here are some examples:
And, again The Special Case, which occurs if we have the same linear regression of x2 on x1, in both classes. As we have seen before, for this constellation of variates, the error increases as
![]() .
.
If all variates have linear regressions on a set of k variates, these k variates determine an upper limit that can be attained by the squared distance, no matter how many variates are included in the discriminant. It is important to notice that regressions must be THE SAME IN BOTH CLASSES.