2. Context in Image Classification
a. Lower Order Markov Chains3. Context in Text Recognition
b. Hilbert Space Filling Curves
c. Markov Meshes
d. Dependence Trees
a. A Quick Bit on Compound Decision Theory
b. Dictionary Look-up Methods
3. Context in Text Recognition
b. Dictionary Look-Up Methods
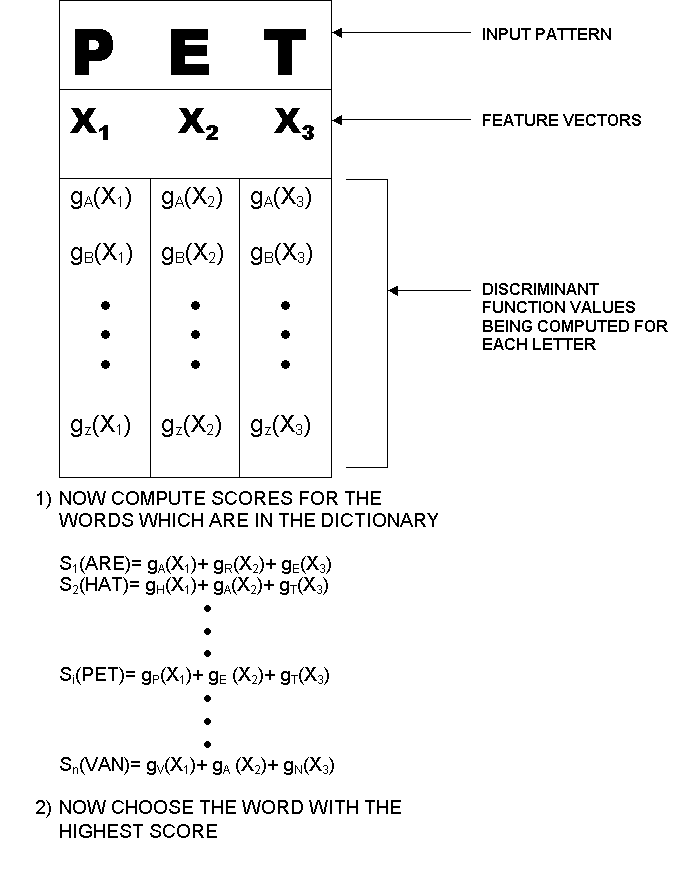
Dictionary look-up methods are one of the oldest methods for text recognition, especially for speech and for cursive speech. The method is quite simple. Consider the word PET input into a machine and the job of the machine is to determine what the word is based on the determining what the word actually is.What follows is the method that is used in order to make this determination:
1) When the PET is input into the machine, and a feature vector, X={X1, X2, X3}, is formed for each letter in the word. The feature vector is determined based on features of each letter. One manner of recording features was done in the MIT reading machine for the blind, and is an example how feature vectors can be computed. Another way is to use compound decision theory that was discussed in the previous section.
2) A discriminant function, gd(Xi) is then calculated in order to get some sense of confidence to determine what each letter in the word should be. This means that given some feature vector, Xi, that some class d is actually the true class. The true class consists of the letters of the alphabet, therefore the solutions are in fact {A, B, ... Z}.
3) Assume that there are n words with length 3 in the dictionary. It can be decided upon which word is actually the correct one based on a scoring function Si(*), i=1,2,...n. * is the word that we are computing the score for.
4) We then choose the word with the highest score.
The following figure demonstrates
pictorially how dictionary look-up methods can be used.
Assume that a mistake was made when entering the letters, and like in the examples on the previous page the word "THE" is mistaken for "TAE". Therefore three letter error correction must be performed because we know that word "TAE" does not exist. Therefore, from what was discussed in compound decision theory we must maximize the a posteriori probability of the classes d1, d2, and d3 given that we have the word TAE or by using Bayes decision rule and taking logarithms we can say that:
![]() .
.
We are calculating this expression
for all words of length three in the dictionary and the word with the highest
score is chosen.
Previous : 3a.
A Quick Bit on Compound Decision Theory
Next: Conclusions