2. Context in Image Classification
a. Lower Order Markov Chains3. Context in Text Recognition
b. Hilbert Space Filling Curves
c. Markov Meshes
d. Dependence Trees
a. A Quick Bit on Compound Decision Theory
b. Dictionary Look-up Methods
3. Context in Text Recognition
Human beings are much better than machines in "decoding" hand-written text. We are able to spot errors in which words are misspelled and we are also able to decode different types of handwriting and several different types of machine printed text. Psychological tests have showed that human beings are able to recognize words as a whole based on word features or information that forms the word, and from that they can determine what the individual letters in the word must be. It can then be said that letter recognition in the context of words is top-down and not bottom-up.Some methods machines and computers can use word recognition rather than trying to segment each letter. Therefore, in order to determine what a word is, we must determine what the "word features" are. These features are the following: graphalogical, phonological, statistical, syntactic, semantic, and pragmatic.
1) GRAPHILOGICAL
These features are the features which characterize the shape of a word or the shape the letters make in the word. One example of a graphalogical feature is the height to width ratio of a word. Contextual information can also be transmitted in the form of printing style. The example shown in Toussaint is the following
This is my crudely drawn rendition of what appears in the paper. But in the above examples of hyper and bed, we see that the P strongly resembles the D. Of course this can happen in any situation where hand written text needs to be identified. Here there is ambiguity in recognizing the text which is here, but the ambiguity is resolved by being able to resolve the graphalogical features.
2) PHONOLOGICAL
Humans have an a priori knowledge of what a word or certain words are supposed to sound like and what sound to expect in certain situations.
3) STATISTICAL
This type of information is present in that more frequently occuring words are more familiar to us and are also more easily recognized . Here the frequency of occurrence of letters, letter pairs, and letter triplets are all examples of rules which can be used when using contextual information.
4) SYNTACTIC
These are the features which
are present in the construction of words and sentences. This means
having the correct grammar, and being able to determine the features of
words based on sentence construction, or the letters in the construction
of a word. Some examples of general rules are the following:
a) No more than two or more consecutive vowels
b) No more than three or more consecutive consonants
c) Consonants and only the vowels a and e can occur at the beginning of a word
d) No word can end in a vowel or with the consonant h.
5) SEMANTIC
These are the features which indicate the meaning of words. Some examples which are hand drawn simulations are presented below.
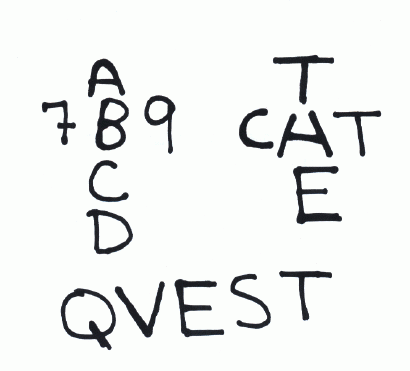
Let us consider each case individually. Consider first the example in the upper left. Here it is known that we are distinguishing words and numbers. Therefore it is far more likely that a "B" will follow the letter "A" and an "8" is more likely to follow the "7".
Similarly in the example in the upper left we are asked to distinguish between the letters "A" and "H". Here we know that the words CHT and TAE are illegal.
Similarly in the bottom must example we know that the letter "V" cannot follow the letter "Q", therefore the word must be QUEST and not QVEST. We also know that the letter "Q" is normally followed by the letter "U" and not "V".
6) PRAGMATIC
These are features based on how the user uses the word. For example, cursive hand writing.
Most computer methods for
text recognition use syntactic and statistical methods in order.
The approaches include: dictionary look-up methods, probability distribution
approximation techniques and hybrid methods. All of these methods
require knowledge of Bayes'
decision theory which will not be covered here.
Previous : 2d.
Dependence Trees
Next: 3a
A Quick bit on Compound Decision Theory